○ 활성화 함수
활성화 함수는 이전 층(layer)의 결과값을 변환하여 다른 층의 뉴런으로 신호를 전달하는 역할을 한다. 활성화 함수가 필요한 이유는 모델의 복잡도를 올리기 위함인데 앞서 다루었던 비선형 문제를 해결하는데 중요한 역할을 한다.
비선형 문제를 해결하기 위해 단층 퍼셉트론을 쌓는 방법을 이용했는데 은닉층(hidden layer)를 무작정 쌓기만 한다고 해서 비선형 문제를 해결할 수 있는 것은 아니다. 활성 함수를 사용하면 입력값에 대한 출력값이 비선형(nonlinear)적으로 나오므로 선형분류기를 비선형분류기로 만들 수 있다.
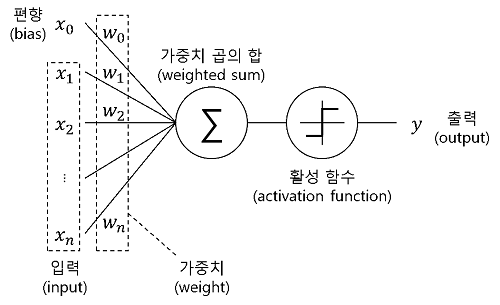
신경망에서는 활성화 함수로 비선형 함수만을 사용하게 되는데 선형 함수를 사용하면 신경망의 층을 깊게 쌓는 것에 의미가 없어지기 때문이다. 즉, 은닉층(hidden layers)이 없는 네트워크로도 똑같은 기능을 할 수 있다.
예를 들어, 활성화 함수를 $h(x) = cx$ 라고 하자. 3층으로 구성된 네트워크라 할 때, $y(x) = h(h(h(x))) = c*c*c*x = c^3*x$이다. 이는 곧 $y = ax$에서 $a=c^3$인 선형 함수이며 1층으로 구성된 네트워크와 다를 바가 없어진다.
활성화 함수는 여러 종류가 있으며 종류에 따라서 신경망의 효율이 달라질 수 있다. 실제로 퍼셉트론은 임계값(이항하면 bias로 인식)을 경계로 출력이 바뀌는데 이는 계단함수를 활성화 함수로 사용하는 경우이다.

● 시그모이드(Sigmoid) 함수
신경망에서는 가중치를 학습시키는데 있어 미분을 사용해야했기 때문에(오차역전파법의 원리) 활성화 함수로 계단함수를 사용할 수 없었다(계단 함수는 미분이 불가능). 또한, 계단함수는 0/1과 같은 극단적인 값을 전달하기 때문에 데이터의 정보를 손실시켰다. 따라서, 계단함수를 곡선의 형태로 변형시킨 형태의 시그모이드(sigmoid) 함수를 적용하게 되었다. 시그모이드는 우리가 흔히 알고 있는 로지스틱(logistic) 함수이다.
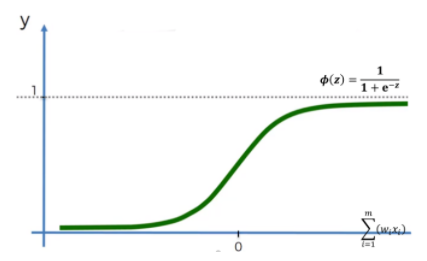
계단함수와 비교해보면, 시그모이드 함수는 선이 매끄럽기 때문에 입력에 따라 연속적인 실수값을 출력하는데 입력이 중요하면 큰 값을, 중요하지 않으면 작은값을 출력한다. 이처럼 시그모이드 함수를 이용하면 계단함수보다 데이터의 정보를 보존할 수 있다.
하지만, 시그모이드 함수도 단점이 존재하여 최근에는 잘 사용되지 않는다.
- Gradigent Vanishing : 층이 많아질수록 오차역전파 수행시 기울기가 소실되는 문제가 발생한다.

미분함수에 대해 $x=0$ 에서 최대값(0.25)을 가지고, 입력값이 점점 작거나 커질수록 기울기가 거의 0에 수렴(saturation)하게 된다. 따라서, 가중치가 갱신이 되지 않으며 학습이 중단되게 된다.
- 함수값 중심이 0이 아니다(non-zero centered) : 입력값이 항상 양수이기 때문에 가중치에 대한 기울기($\frac{\partial L}{\partial w}$)가 항상 양수 또는 음수가 되어 학습이 잘 안될 수 있다. (zigzag 문제)

- exp( ) 연산으로 시간이 오래 걸린다.
+ 시그모이드는 은닉층에 활성화 함수로도 사용되지만 출력층에 output function으로도 사용된다. 이는 결과값을 0~1사이의 값으로 추출하기 위해서이며 분류(classification) 문제에서 사용된다.
● 하이퍼블릭 탄젠트(Hyperbolic Tangent) 함수
시그모이드 함수값의 중심을 0으로 맞추기 위해 개선된 함수로, 결과값이 (-1, 1) 사이이면서 양수와 음수가 나오는 비중이 비슷하기 때문에 zigzag 현상이 덜하다. 하지만, 여전히 기울기 소실문제가 있어서 가중치 학습이 중단되게 된다. 또한 exp( ) 연산이 더 많아서 시간이 오래 걸린다.

● 렐루(ReLU : Rectified Linear Unit) 함수

입력값이 양수인 경우만 뉴런을 전달하는 함수이다. 양의 값에서는 saturation되지 않는다. 시그모이드나 tanh보다 손실함수의 수렴속도가 6배 정도 빠르다. 하지만, 함수값의 중심이 0이 아니라는 문제가 발생한다.(zigzag 문제)
=> saturation은 막을 수 없지만, 시그모이드나 tanh보다 접선의 기울기가 0이 되는 부분이 적기 때문에 ReLU가 가중치를 업데이트하는 속도가 빨라져 성능이 좋다.
그 밖의 다양한 활성화 함수가 존재하며,

<참고 문헌>
muzukphysics.tistory.com/165?category=1111219
'Deep Learning > 딥러닝' 카테고리의 다른 글
| 소프트맥스(Softmax) 함수 (1) | 2021.02.25 |
|---|---|
| 퍼셉트론(Perceptron)과 오차역전파(Backpropagation) (1) | 2021.02.18 |
| 인공지능? 머신러닝? 딥러닝? (1) | 2021.02.16 |



댓글