본 포스팅은 제목과 같이 ISLR(Introduction to Statistical Learning with R)이라는 책을 바탕으로 쓰여질 것이다. 이 책은 통계학 학부 수준에서 이해가 가능한 정도라고 생각하면 좋다. 최대한 간단하면서 뼈대를 세워가며 정보를 전달하기 위해 노력할 것이며, 포스팅의 끝에서는 전체적인 개요가 머릿속 안에 잡히는 것이 목표이다.
Statistical learning은 f를 추정하는 접근법 set이다. 이 도구들은 크게 지도(supervised) or 비지도(unsupervised)로 나뉘며, supervised statistical learning은 한 개 이상의 X(독립변수)로 Y를 예측, 추정하기 위한 통계적 모형을 만드는 것이고 unsupervised statistical learning은 Y를 나타낼 필요가 없는 경우에 쓰이는 통계적 모형으로 모두 X(독립변수)로 간주하여 데이터들간의 관계나 구조를 파악할 때 사용한다.
- f를 추정하는 이유
f를 추정하는 이유로 prediction(예측)과 inference(추론)이 있다.
(1) 예측
실제로 X(독립변수)는 이용하고 접근하기가 쉽지만, Y(종속변수)는 쉽게 얻을 수 없는 경우가 많다. 따라서 f를 추정하여 X를 통해 Y를 예측하게 된다.
$\hat{Y} = \hat{f}(X)$
예측값 $\hat{Y}$에 대한 정확성은 두 가지 값으로 판단할 수 있다. (irreducible error, reducible error) $\hat{f}$는 추정된 함수일 뿐이지 실제 f와 동일한지는 알 수 없다. 그렇기 때문에 분명 error가 발생하며, 이를 reducible error라고 한다. reducible error는 f를 추정하는 방법에 따라 달라지며 좋은 모델을 사용하여 error를 줄일 수 있다. 그래서 이름도 줄일 수 있는 오차이다. 반면, irreducible error는 Y가 $\epsilon$의 함수라는 점에서 발생한다. 따라서, $\epsilon$과 관련된 변동성은 예측정확도에 영향을 주며 아무리 좋은 모델을 사용한다 하더라도 줄일 수 없다.

(2) 추론
우리는 종종 Y를 예측하는 것 외에도 X에 따라 Y가 어떻게 변하는지 궁금할 때가 있다. X와 Y의 관계가 궁금한 경우, 다음의 질문들을 할 수 있다.
- 어떤 X변수가 Y변수와 관련이 있는가?
- Y변수와 X변수 사이는 양의 상관/음의 상관인가?
- Y변수와 X변수 사이의 관계는 선형/비선형으로 설명될 수 있는가 ?
이와 같은 질문을 던져가며 X에 따라 Y가 어떻게 변하고 그들의 관계가 어떻게 이어졌는지에 분석목적을 둘 수 있다.
- 모수적인 방법과 비모수적인 방법
그렇다면, 어떻게 unknown f(x)를 추정할 수 있을까? 이 책에서는 선형적 또는 비선형적으로 접근하는 방법을 소개할 것이다. 또한 각 접근 방식에서 f에 대해 분포가정을 하는지 안하는지에 따라 모수적인 방법과 비모수적인 방법으로 나뉠 수 있다. 모수적인 방법과 비모수적인 방법에 대해 좀 더 자세히 알아보자.
parametric methods 은 두단계에 걸친 모델 기반의 접근(model-based approach)이 필요하다.
첫번째는 f에 대한 형태를 가정한다. 예를 들어, f는 X들의 선형으로 이루어져 있다. 다음의 모형을 선형 모형이라고 한다.
$f(X) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \dots + \beta_p X_p.$
f를 선형함수로 가정하면, f의 추정은 매우 간단해진다. 임의의 p차원 함수 f(x)를 추정하는 대신에 선형함수는 p+1개의 회귀계수만 추정하면 된다.
두번째는 모형이 선택된 후에 우리는 모형을 적합 or 훈련시키기 위해 training data를 사용해야한다. 즉, 선형 모형에서는 다음의 관계를 만족하는 모수 $\beta_0, \dots, \beta_p$를 추정해야하며 이때 training data를 이용한다. 선형회귀모형에서 모수를 추정하는 가장 기본적인 방법은 최소제곱법 (ordinary least squares)이다. 이 외에도 다양한 방법이 있으며 6장에서 다룰 것이다. 이러한 모델 기반의 접근을 모수적인 방법이라고 한다. 모수적인 방법은 전체적으로 가능성을 열어둔 임의의 f를 추정하는 문제를 단순히 모수의 set를 추정하는 문제로 감소시킨다. 모수적인 방법의 단점은 우리가 가정한 모델이 true f와 다를 수 있다는 것이다. 만약 선택한 모형이 true 와 매우 다르다면, 우리의 추정은 좋지 못할 것이다. 하지만, 유연한 모델을 가정한다해도 과적합의 문제가 발생하기 때문에 추정이 좋지 못하는 똑같은 문제를 겪을 수 있다.
non-parametric methods 는 f의 형태에 대해 가정을 하지 않는다. 대신에 너무 구불구불하지 않으면서 가능한 데이터에 가깝게 추정한다. 이러한 접근은 모수적인 방법과는 반대로 넓은 범위에서 f가 가질 수 있는 형태를 적합할 수 있다는 장점을 가진다. 모수적인 방법은 f의 형태에 대해 가정을 하기 때문에 true f 와 다를 수 있다는 가능성이 있다고 바로 위에서 말했다. 하지만 비모수적 방법은 애초에 f의 형태에 대해 가정을 하지 않았기 때문에 이러한 위험을 피할 수 있다. 비모수적인 방법에서 가지는 단점은 f를 추정하는 문제를 단 모수 몇개를 추정하는 문제로 감소시킬 수 없다는 것이다. 따라서, 많은 관측치가 필요하게 된다.
- 예측 정확도와 모델 해석력의 trade-off 관계
모수적인 방법은 작은 범위에 대해 분포를 생성하기 때문에 상대적으로 유연하지 않으며 제한적이다, 반면 비모수적인 방법은 넓은 범위에서 최대한으로 가능한 분포를 생성하기 때문에 중 상당히 유연한 방법이다. 그렇다면 우리는 왜 더 제한적이고 유연하지 못한 방법을 사용해왔을까? 우리가 더 제한적인 모델을 사용하는데에는 몇가지 이유가 있다.
1. 만약 주 목적이 추론(Inference)라면, 제한적인 모델은 훨씬 더 해석력이 좋을 것이다. 예를 들어, 선형 회귀의 경우 X와 Y의 관계를 다른 어느 것보다 쉽게 나타낼 수 있으면서 해석을 하기에 용이하다. 반면, splines 또는 boosting과 같은 매우 유연한 방법은 f 를 다소 정교하게 추정하기 때문에 X와 Y의 관계를 이해하기 어렵다.
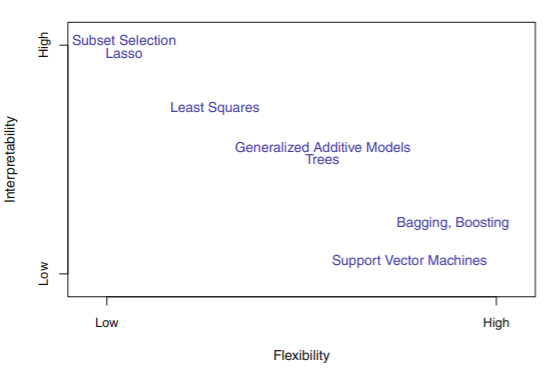
모델의 유연성과 해석력의 trade-off 관계를 나타낸 것이다. linear 모형은 상대적으로 모델이 단순하지만 해석하기 편하다. lasso 모형은 linear 모형에서 회귀계수에 제약을 더 주어 0으로 수렴하게 만든다. 따라서, linear 모형보다 더 단순한 모델이 만들어진다. GAMs 모형은 linear 모형의 확장된 버전으로 X와 Y의 관계를 non-linear하게 곡선으로 설정한 것이다. 따라서 linear 모델보다 더 유연하지만 해석력이 낮다. 마지막으로 fully non-linear 방법인 배깅, 부스팅, 서포트벡터 머신은 매우 유연한 모델로 해석하는데 어려움이 있다.
따라서, 추론이 목적일 때는 상대적으로 덜 유연하고 간단한 모델을 사용하는 것이 유용하다. 하지만 예측이 목적인 경우에는 X와 Y의 관계에는 관심이 없기 때문에 복잡한 모델을 사용하는 것이 유용하다. 조심해야할 점은 분석의 상황이 항상 이렇게 깔끔하게 나뉘어지지 않는다. 때때로 간단한 모델을 사용하여 더 정확한 예측력을 얻을 수 있다. 이는 복잡한 모델로 적합을 했을 때 과적합이 발생할 수 있다는 것이다.
- 대부분의 statistical learining 문제는 크게 지도(supervised) or 비지도(unsupervised)로 나뉘며, 아주 단순하게 Y가 있고 없는 차이라고 생각할 수 있다. 지도학습은 관측값 X, Y가 모두 있으며 이 관계를 학습시켜 추론 or 예측을 목적으로 모형을 적합한다. 비지도 학습은 관측값 X만 가지고 있으며 X들 간의 관계를 파악하는 분석에 사용한다. 비지도 학습의 예로는 군집분석이 있다. 군집분석의 목표는 x1,..., xn의 기반으로 각 관측값이 어떻게 그룹지어지는지 분석하는 것이다.

위의 그림은 군집분석을 수행한 예시이다. 두 변수(X1, X2)에 대해 150개의 관측값을 산점도에 표시한 것으로 군집분석을 수행한 결과 3그룹으로 나뉜다는 것을 볼 수 있다. 그러나 실제로 그룹의 수는 알 수 없으며, 목표는 각 관측값이 어느 그룹에 속하는지 결정하는 것이다. 왼쪽의 예시는 그룹이 상대적으로 잘 나뉜것으로 보이나, 오른쪽 예시는 그룹간에 다소 겹치는 부분이 있다. 이와 같이 군집분석의 문제는 그룹간에 겹치는 점들이 올바른 그룹에 속한다고 장담할 수 없다는 것이다. 그리고 위의 예시는 쉬운 예시로 2차원을 고려하였지만, 실제로는 p차원(>2)인 데이터를 만나게 될것이다. 이런 경우 p(1-p)/2개의 산점도를 만들 수 있으며, 시각적으로 군집을 파악하기 매우 불가능해질 것이다. 이런 이유로 automated clustering 방법은 매우 중요하며 이에 대한 군집 방법과 다른 비지도 학습 접근은 10장에서 다룰 것이다.
많은 문제들이 지도 or 비지도 학습으로 나뉜다고 했지만, 때때로 이 둘 사이로 명백하게 나뉘어지지 않는 경우도 있다. 일부는 y가 있고 일부가 없는 경우 이를 semi-supervised learning이라고 한다. 이런 것이 있다는 정도만 알아두고 이 책에서 다루지는 않는다.
- 회귀와 분류의 문제
변수의 특성은 연속형(양적)과 범주형(질적)으로 나뉜다. 연속형 변수는 숫자의 값을 취하며, 범주형 변수는 값이 k개의 범주 중 하나로 나타내진다. 일반적으로 Y가 연속형인 경우를 회귀(Regression), 범주형인 경우를 분류(Classification) 로 다룬다. 로지스틱 회귀는 Y가 범주일 때 분류 목적으로 사용하지 않나 ? 라는 의문이 들을 수 있다. 엄연히 말하자면, Y가 특정 범주에 속할 확률을 추정하는 것이기 때문에 회귀라고 할 수 있다. Knn이나 부스팅과 같은 방법은 Y가 연속형, 범주형과 상관없이 사용될 수 있다. X가 연속형인지 범주형인지는 중요하지 않다. 범주형 변수는 분석이 수행되기 전에 알맞게 재코딩될 것이며 이는 3장에서 다룬다.
- 모델의 정확도 평가
주어진 자료에 대해 최고의 성능을 가지는 방법을 선택하는 것 또한 매우 중요하다. 이는 예측값과 실제 관측값이 얼마나 잘 일치하는지로 파악할 수 있다. 회귀가 목적인 경우, 흔히 사용되는 측정 기준은 MSE(Mean Squared Error)이다.
$MSE = \frac{1}{n} \sum_{n}^{i=1} (y_i - \hat{f}(x_i))^2$
여기서, $\hat{f}(x_i)$은 i번째 관측값에 대한 예측값이다.
예측값과 실제 관측값이 가까울수록 MSE는 작을 것이고, 다를수록 MSE는 커질 것이다. training set에 대해 구해지는 MSE는 training MSE로 보다 정확하게 언급할 수 있다. 하지만, 우리가 관심있는 것은 모형을 훈련시킬때 사용하지 않은 새로운 test data에 대해 모형이 얼마나 정확하게 맞추는가이다. 즉, 우리는 가장 작은 test MSE를 가지는 모형을 선택할 것이다. 다시말하면 우리가 많은 test data를 가진다면 다음의 평균 제곱 예측 오차(average squared prediction error)를 구할 수 있고, 가능한 작은 값을 가지는 모형을 선택한다.
$Ave(\hat{f}(x_0) - y_0)^2$
그렇다면 test data가 없는 경우, test MSE를 구할 수 없게되는데 이럴때는 어떻게 모형을 선택할 수 있을까? 대안적으로 training MSE를 최소로 하는 모형을 선택한다. 하지만, 이러한 대안에는 근본적인 문제를 가지고 있다. training MSE가 가장 작은 모형을 선택했다고 해서 그 모델의 test MSE가 가장 작다고 할 수 없다는 것이다. 모형은 training data에 의해 훈련이 되므로 회귀계수 또한 training data에 최적화되어 추정될 것이다. 따라서 test MSE 는 training MSE보다 클 수 밖에 없다.



빨간 곡선은 test MSE이며, training MSE와 함께 초기에 모형의 유연성이 증가함에 따라 감소한다. 그러나, 어느 시점에서 변동이 없다가 다시 증가하기 시작한다. 결과적으로 주황 직선과 초록 곡선 둘다 높은 test MSE를 가진다. 파랑 곡선은 test MSE를 최소화 시킨다. 수직 점선은 $Var(\error)$ = irreducible error 이며, 가장 낮게 측정될 수 있는 test MSE 이다. 모형의 유연성이 증가하면서 training MSE는 감소하는 형태를 띠고, test MSE는 U자 형태를 띤다. 이는 특정데이터나 모형에 상관없이 가지는 성질이다. 이를 우리는 데이터에 과적합(overfitting) 되었다고 한다. 과적합이 발생하는 이유는 모형이 training data를 너무 열심히 학습했기 때문이다. 모형이 training data에 대해 과적합 되었을 때, test MSE는 매우 클 것이며, 이는 모형이 training data에서 찾은 패턴이 test data에는 없기 때문이다. 과적합의 문제에 상관없이 training MSE는 test MSE보다 작을 것이다. 대부분의 선택모형은 training data를 기준으로 선택되었기 때문이다. 따라서 정확하게 집고가기 위해, 과적합은 덜 유연한 모형이더 작은 test MSE를 산출한 경우를 말한다.
- the bias-variance trade off
test mse는 3가지의 특성으로 분해될 수 있다.
$E(y_0-\hat{f}(x_0))^2 = Var(\hat{f}(x_0)) + [Bias(\hat{f}(x_0))]^2 + Var(\epsilon)$
좌측표기는 expected test MSE 로 정의되며 평균 test MSE를 의미한다. 위 값은 training set을 반복적으로 이용하여 f를 추정한다음 test data에 의해 매겨진다. test MSE를 최소화 시키는 것이 목적이며, 이를 위해서는 variance와 bias를 동시에 낮추는 방향으로 진행되어야한다. variance와 bias는 특징적으로 음의 값을 가지지 않는다. 따라서, expected test MSE는 Var($\epsilon$)보다 절대 작을 수 없다. variance는 여러 training data를 사용하여 f를 추정할 때 f가 변화하는 정도를 의미한다. 만약 statistical learning method가 높은 분산을 가진다면 training data의 작은 변화에도 f를 추정할 때 큰 변화를 초래할 것이다. 일반적으로 더 유연한 통계적 모형은 높은 분산을 가진다. 위의 그림을 봤을 때 초록색과 주황색의 곡선이 그 예이다. bias는 모델이 얼마나 true 모델가 비슷한지에 대한 오차이다. expected f의 평균이 true 값과 같을 때 unbiased하다 하고 한다. 일반적으로 더 유연한 방법이 작은 bias를 발생시킨다.
보통 우리는 더 유연한 모델을 사용하기 때문에 분산은 높고 편향은 낮을 것이다. 두 값의 상대적인 변화율은 test MSE를 증가시킬건지 감소시킬건지를 결정한다. 모델의 복잡도를 높였을 때, bias는 variance가 증가하는 것보다 훨씬 더 빠르게 감소하며, 결과적으로 expected test MSE는 감소한다. 다시말하면, 복잡도를 증가시키는 것은 bias에 영향을 미치지는 않지만 variance가 상당히 증가하게 된다. 이는 위의 그림에서 test MSE가 감소했다가 복잡도가 올라감에 따라 test MSE가 증가는 모습을 설명한다.

위 그림은 true f 의 형태에 따른 test MSE (variance + bias + irreducible error)이다. 위에서 모형의 적합도에 따른 test MSE를 본것을 bias 와 variance , irreducible error로 쪼갠 것이다. 첫번째 그림을 보면 true model이 non-linear하기 때문에 모형의 복잡도가 증가할수록 bias는 감소하고 variance는 증가하는 것을 볼 수 있다. 중간 그림을 보면 true model이 linear 하므로 적합한 모형의 bias가 기본적으로 작으며, 모델의 복잡도가 증가할수록 variance가 커진다. 마지막 그림은 true model이 매우 non-linear하다. 따라서 모델의 복잡도가 증가하더라도 variance에 거의 영향이 없다.(살짝 증가)
우리는 작은 variance와 bias를 가지는 모형을 선택하길 원하지만, variance가 작아지면 bias는 커지고 bias가 작아지면 variance가 커지는 상황에 직면할 수 밖에 없다. 이를 trade-off 관계라고 말한다.
-classification
지금까지 y가 수치형(회귀)인 경우 모델의 성능을 나타내는 test MSE에 대해 알아보았다. 그렇다면, y가 범주형(분류)인 경우에는 모형의 성능을 어떻게 평가할 수 있을까? 가장 흔한 접근은 training error rate 이다. 이는 적합모형에 training 관측값을 넣고 오분류율을 구하는 것이다.
$\frac{1}{n}\sum_{i=1}^{n} I(y_i \neq \hat{y}_i)$
i번째 관측값이 i번째 적합값과 같지 않으면 카운트를 세는 지시함수이다. 오분류 수에서 전체 관측치 수를 나눠 오분류율을 구한다. 회귀에서와 마찬가지로 분류도 test data에 대해 오류율이 낮은 모형을 찾는 것이 목적이다.
(출처)
An Introduction to Statistical Learning with Applications in R (Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani)
'Statistics > ISLR' 카테고리의 다른 글
| Ridge / Lasso regression (0) | 2021.05.21 |
|---|---|
| 6. Linear Model Selection and Regularization (0) | 2020.10.25 |
| 3. Linear regression(선형 회귀) (0) | 2020.10.08 |
| Resampling Method(Hold-out, Cross-Validation, Bootstrap) (0) | 2020.10.05 |
| Ridge regression (0) | 2020.04.08 |




댓글